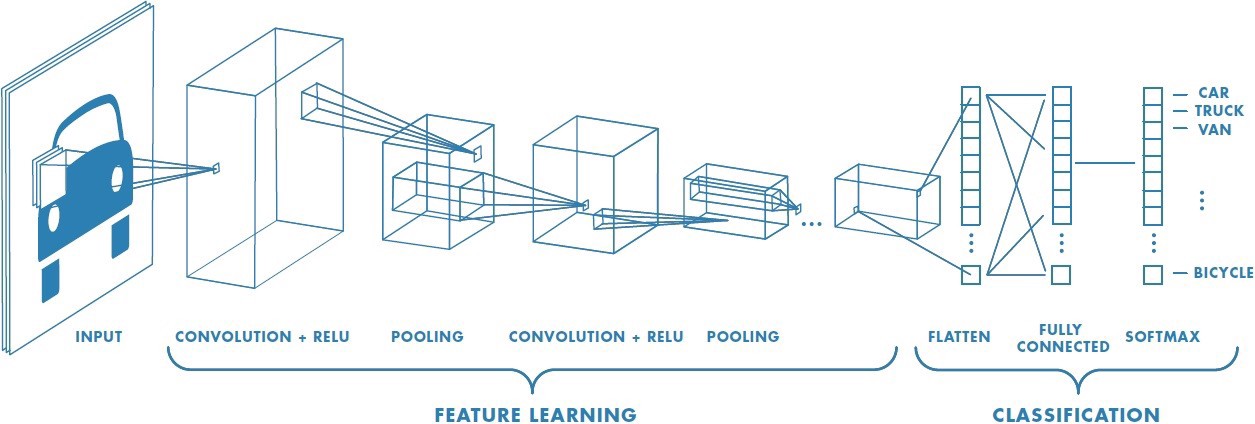
Mạng nơ-ron nhân tạo (Neural network) là một kiến trúc được lấy cảm hứng từ mạng nơ-ron thần kinh của con người. Với các tiến bộ của khoa học cũng như việc ứng dụng các công nghệ học sâu (Deep learning), Neural Network đã trở thành một công cụ mạnh mẽ giúp giải quyết rất nhiều bài toán khó như xử lý, nhận dang ảnh (Computer Vision), giọng nói (Speech processing), xử lý ngôn ngữ tự nhiên (Natural language processing). Trong bài này ngoài việc khái quát chung những phần tử cấu trúc cơ bản của một mạng Neural Network chúng ta sẽ tìm hiểu thêm về cấu trúc Convolution net - một cấu trúc cơ bản cấu thành nên các mạng NN,DL hiện tại
Mục lục
Neural Network
Noron
Mạng nơ-ron là mạng được lấy cảm hứng từ mô hình não người. Với cấu tạo từ $10^{11}$ nơron và $10^{14}$ kết nối não người có thể thực hiện được rất nhiều các tác vụ phức tạp mà hiện tại vẫn chưa có mô hình “AI” nào bì kịp. Tương tự như vậy thì các mạng NN cũng được cấu tạo bới các nơron ( node mạng) cùng với đó là kết nối giữa các node đó với nhau. Dưới đây là một mô phỏng 1 node mạng ở dạng đơn giản
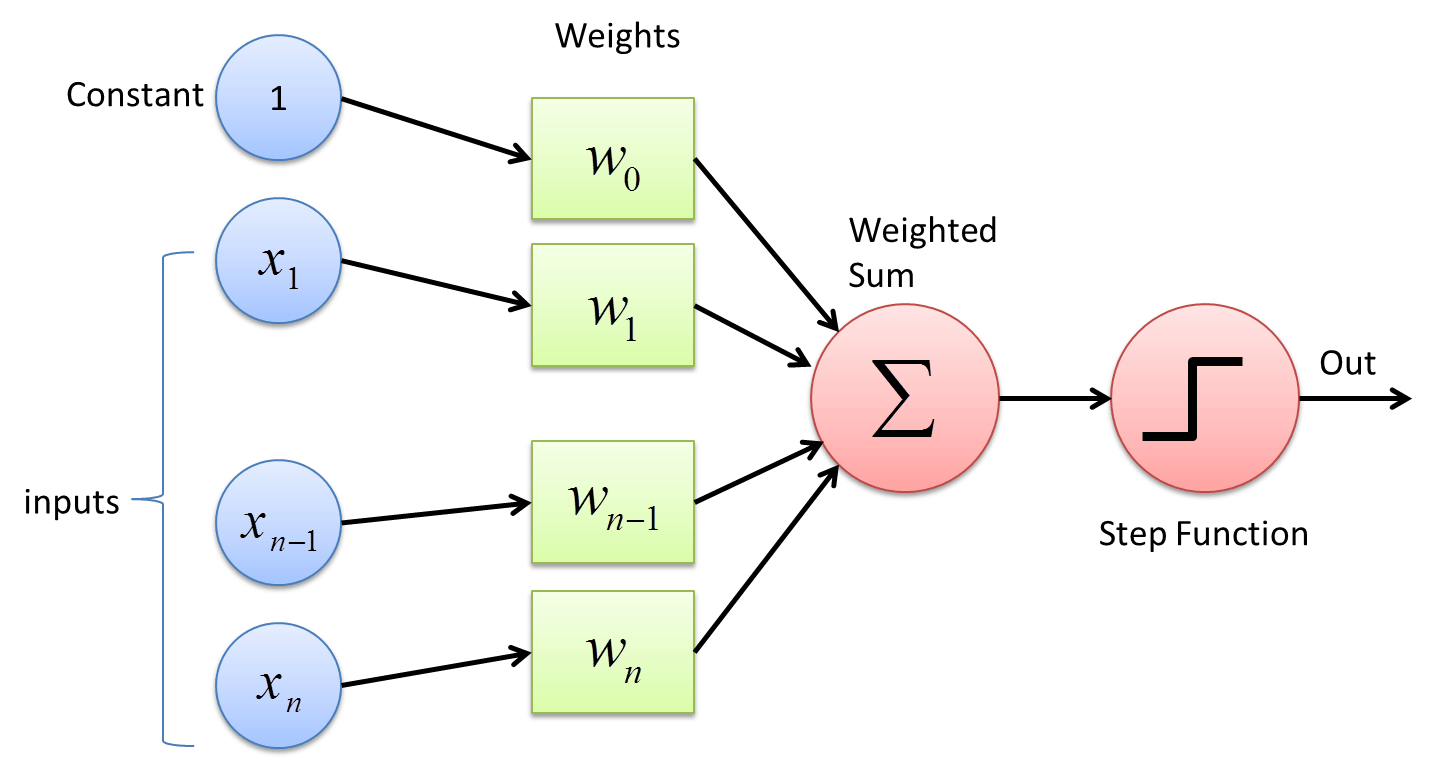
Như hình trên, một node sẽ nhận một hoặc nhiều đầu vào $\mathbf{x}$ và cho ra một kết quả $o$ duy nhất. Các đầu vào được điều phối tầm ảnh hưởng bởi các trọng số (weights) tương ứng $\mathbf{w}$ của nó, còn kết quả đầu ra được quyết định dựa vào một ngưỡng (bias) quyết định $b$ thông qua một Step Function (Sigmoid, Tanh, Relu, v..v) :
Có một lưu ý là các hàm activation luôn là các hàm phi tuyến (non-linear). Tại sao cần dùng hàm phi tuyến mà không phải là một hàm tuyến tính. Lí do xuất phát chính từ cấu trúc của các mạng NN, giả sử chúng ta đều sử dụng các hàm tuyến tính để làm activation thì không khác gì việc chúng ta dùng thêm 1 tầng ẩn nữa vì các phép biến đổi cũng chỉ đơn thuần là nhân thêm với một trọng số $w$ nào đó. Với các phép biến đổi đơn gỉan như vậy thì mô hình NN sẽ không có khả năng học được những mối quan hệ giữa các dữ liệu, cũng không có khả năng giải quyết được những bài toán phức tạp như xử lý ảnh hay xử lý ngôn ngữ tự nhiên. Chúng ta có thể mô tả đơn gỉan hoạt động của 1 noron bằng công thức dưới :
Đặt $b=-\text{threshold}$, ta có thể viết lại thành:
Để dễ hình dung, ta lấy ví dụ việc có bị vợ đánh hay không phụ thuộc vào 3 yếu tố sau:
- Bạn có chịu nộp tiền hàng tháng cho vợ hay không
- Bạn có chịu làm việc nhà hay không ?
- Bạn có hay đi nhậu không ?
Thì ta coi 3 yếu tố đầu vào là $x_1, x_2, x_3$ và nếu $o=0$ thì ta không bị vợ đánh còn $o=1$ thì ta bị đánh. Giả sử mức độ quan trọng của 4 yếu tố trên lần lượt là $w_1=0.8, w_2=0.1, w_3=0.1$ thì ta có thể thấy rằng việc chịu nộp tiền hàng tháng sẽ ảnh hưởng 80% việc bạn có bị đánh hay không còn 2 việc còn lại chỉ rơi vào khoảng 10%. Nếu gắn $x_0=1$ và $w_0=b$, ta còn có thể viết gọn lại thành:
Kiến trúc mạng Neural Network
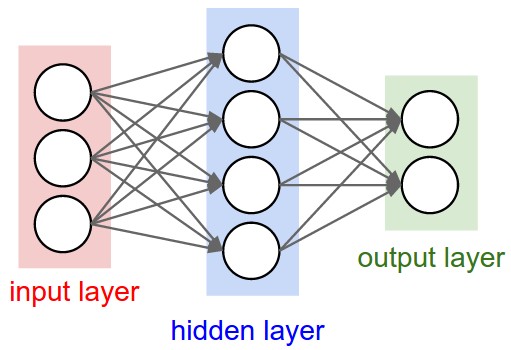
Nói một cách đơn giản, mạng nơ-ron được cấu tạo từ nhiều tầng (layer) lại với nhau. Trong mỗi layer lại bao gồm nhiều nơ-ron (node). Chúng ta có thể chia làm 3 tầng chính :
- Input layer : Là tầng bao gồm các giá trị đầu vào của mạng
- Hidden layer : Có thể gồm 1 hoặc nhiều tầng, các tầng này đóng vai trò như các logic, suy luận của mạng
- Output layer : Thể hiện kết quả đầu ra của mạng
Giữa các tầng có các liên kết bởi những nơron trong mỗi tầng hoặc là giữa các tâng với nhau. Trong mỗi tầng có thể có số lượng nơ-ron khác nhau cũng như các kết nối khác nhau.
Qúa trình học
Như mô hình mạng ở trên chúng ta có thể hình dung nếu ta đưa vào các giá trị Input thì ở đầu ra sẽ có những giá trị tương ứng. Mạng nơ-ron lúc đó sẽ hoạt động như một hộp đen, đơn gỉan là nhận Input và cho ra Output. Vậy cái gọi là traning nằm ở đâu ?. Ở đây chúng ta đề cập đến hai khái niệm Lan truyền tiến và Lan truyền ngược
- Lan truyền tiến (feedforward) : Để ý với mô hình mạng ở trên, thì các node được kết nối một chiều duy nhất từ đầu đến cuối mà không có suy luận ngược lại. Hay chúng ta có thể nói đấy là việc Lan truyền tiến
Với $n^{l}$ là số lượng node ở tầng l , $w_{ij}$ là trọng số , $a^{i}$ là đầu vào của mạng, $b$ là trọng số
- Lan truyền ngược (backpropagation) : Để training mô hình thì sẽ định nghĩa một hàm mất mát. Với các bài toán Supervised Learning, hàm mất mát được hiểu đơn giản là sự sai lệch giữa kết quả đầu ra của mô hình và kết quả thật.
Giả sử có một với cặp dữ liệu $(x_{0}, y_{0})$ ta được kết quả sau khi đưa qua mô hình NN là $(x_{0}, f(x_{0}))$ vậy thì hàm mất mát ở đây chính là sự sai khác giữa $f(x_{0})$ và $y_{0}$. Một mô hình NN được coi là tốt khi mà sự sai khác giữa 2 giá trị trên là nhỏ vậy việc training chính là việc điều chỉnh các tham số $w$ sao cho tối ưu hàm mất mát. Việc tối ưu hàm này như thế nào thì mình sẽ giới thiệu vào một bài khác và sau này khi gặp các network khác mình sẽ cố gắng giải thích thêm về hàm này vì đối với AI/DL thì loss function là thứ quan trọng nhất
Kết luận
Qua bài viết này mọi người đã có những hiểu biết cơ bản về cấu trúc, cũng như quá trình học của một mạng nơron cơ bản. Đây chính là những kiến thức nền tảng nhất với những bạn mới bước chân vào và tìm hiểu về ngành AI.
Mong là bài viết này sẽ có ích cho mọi người :D
 Con đường trở thành AI Engineer
Con đường trở thành AI Engineer